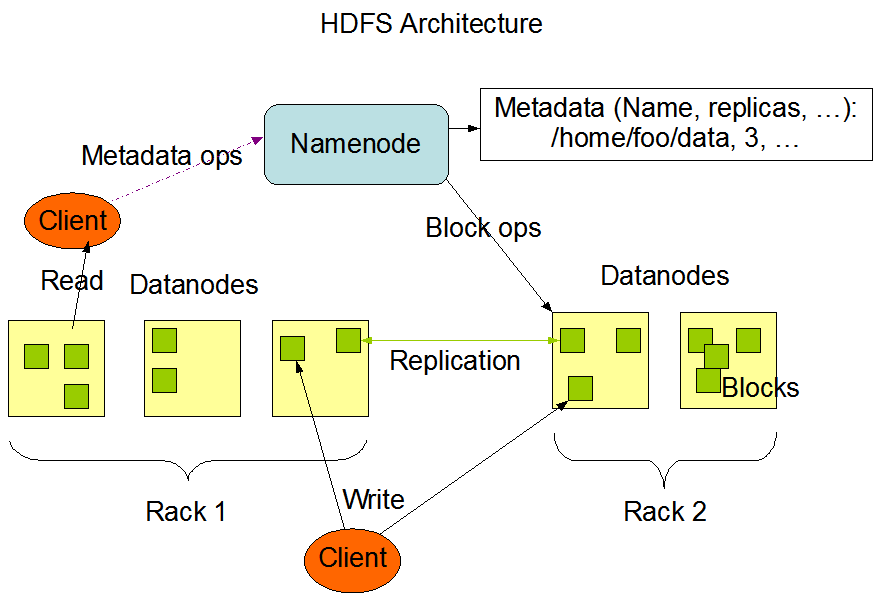
[TOC]
Storm 简介
Storm 是个实时的、分布式以及具备高容错(协调 )的计算系统
- Storm 进程常驻内存
- Storm 数据不经过磁盘,在内存中处理
官网对 Storm 的解释:
Apache Storm is a free and open source distributed realtime computation system. Apache Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. Apache Storm is simple, can be used with any programming language, and is a lot of fun to use!
Apache Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Apache Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
Apache Storm integrates with the queueing and database technologies you already use. An Apache Storm topology consumes streams of data and processes those streams in arbitrarily complex ways, repartitioning the streams between each stage of the computation however needed. Read more in the tutorial.
官网地址: http://storm.apache.org/
Storm 与 MapReduce 的区别
| 计算框架 | Storm | MapReduce |
|---|---|---|
| 概念 | 分布式实时流式计算 | 批处理离线计算 |
| 处理方式 | realtime processing | batch processing |
| 处理数据量的级别 | MB 、KB | TB级 PB级 |
| 单位时间处理数据量 | 小 | 大 |
| 速度 | 快 | 慢 |
| 模型 | DAG 、Spout、Bolt 模型 | Map+Reduce 模式 |
| 生命周期 | 常驻运行 | 反复启停 |
分布式承载数据的方式: 1、切片 2、径向全量 -> ???
Storm 计算模型
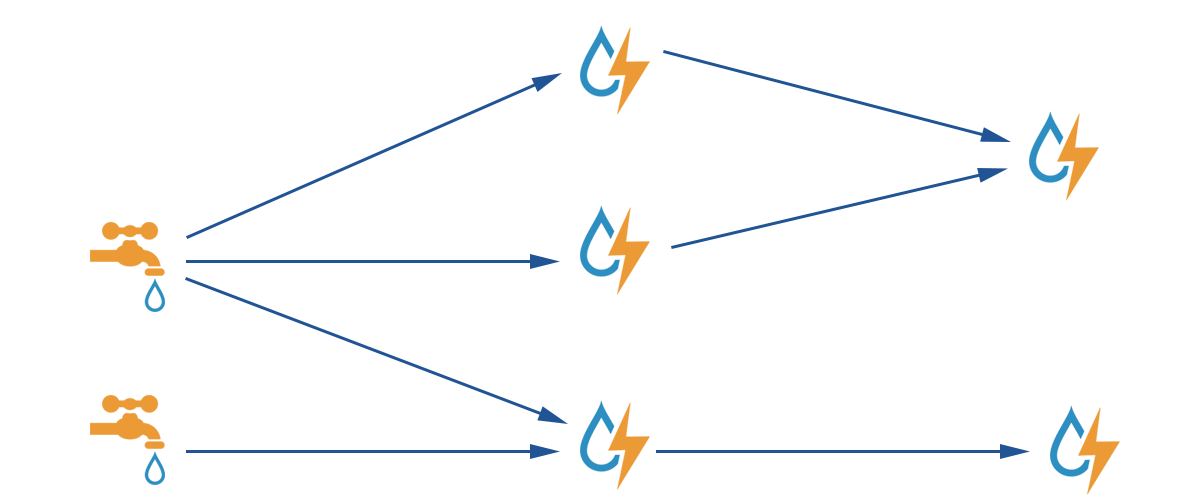
整个图是 DAG(Directed Acyclic Graph)有向无环图
水龙头: 表示数据源 spout
小水滴: 表示一次数据量的大小 tuple
大水滴: 表示一个计算单元 bolt
闪电: 表示计算速度快,就像闪电一样
Storm 应用场景
- 阿里巴巴的 JStorm 项目- 双 11 大屏幕
- 腾讯的 QQ 同时在线人数图
Storm 特点
架构
Nimbus
Supervisor
Worker编程模型
DAG (Topology)
Spout
Bolt数据传输
ZMQ(twitter早期产品)-ZeroMQ 开源的消息传递框架,并不是一个MessageQueueNetty-Netty 是基于 NIO 的网络框架,更加高效。
之所以Storm 0.9版本之后使用Netty,是因为ZMQ的license和Storm的license不兼容。
高可靠性
异常处理
消息可靠性保障机制(ACK)可维护性
StormUI 图形化监控接口
Storm 计算模型详述
spout 将一个个 tuple 通过流的方式, 发送给一个或多个 blot 处理

- Topology – DAG 有向无环图的实现
对于Storm实时计算逻辑的封装
即,由一系列通过数据流相互关联的 Spout、Bolt 所组成的拓扑结构
生命周期:此拓扑只要启动就会一直在集群中运行,直到手动将其kill,否则不会终止(区别于MapReduce当中的 Job,MR当中的Job在计算执行完成就会终止) - Tuple – 元组
Stream 中最小数据组成单元 - Stream – 数据流
从Spout中源源不断传递数据给Bolt、以及上一个Bolt传递数据给下一个Bolt,所形成的这些数据通道即叫做Stream
Stream声明时需给其指定一个Id(默认为Default)
实际开发场景中,多使用单一数据流,此时不需要单独指定StreamId

- Spout – 数据源
拓扑中数据流的来源。一般会从指定外部的数据源读取元组(Tuple)发送到拓扑(Topology)中
一个 Spout 可以发送多个数据流(Stream)
可先通过 OutputFieldsDeclarer 中的 declare 方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector 中的 emit 方法指定数据流Id(streamId)参数将数据发送出去
Spout中最核心的方法是 nextTuple,该方法会被Storm线程不断调用、主动从数据源拉取数据,再通过emit方法将数据生成元组(Tuple)发送给之后的Bolt计算 - Bolt – 数据流处理组件
- 拓扑中数据处理均有
Bolt完成。对于简单的任务或者数据流转换,单个Bolt可以简单实现;更加复杂场景往往需要多个Bolt分多个步骤完成 - 一个
Bolt可以发送多个数据流(Stream)
可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流 Id(streamId)参数将数据发送出去 - Bolt 中最核心的方法是
execute方法,该方法负责接收到一个元组(Tuple)数据、真正实现核心的业务逻辑
- 拓扑中数据处理均有
- Stream Grouping – 数据流分组(即数据分发策略)
Storm 案例
Storm 数据累加
WsSpout.java: 将消息发送给 Blot
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39public class WsSpout extends BaseRichSpout {
Map conf;
TopologyContext context;
SpoutOutputCollector collector;
int i = 0;
/**
* 初始化
*/
public void open(Map conf, TopologyContext context
, SpoutOutputCollector collector) {
this.conf = conf;
this.context = context;
this.collector = collector;
}
/**
* 获取和发送消息
*/
public void nextTuple() {
i++;
List val = new Values(i);
this.collector.emit(val);
System.err.println("spout----------:" + i);
Utils.sleep(1000); // 休眠一秒
}
/**
* 声明字段名称
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("nums"));
}
}WsBlot.java: 接收消息并处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32public class WsBlot extends BaseRichBolt {
Map stormConf;
TopologyContext context;
OutputCollector collector;
int sum = 0;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.stormConf = stormConf;
this.context = context;
this.collector = collector;
}
public void execute(Tuple input) {
Integer num = input.getIntegerByField("nums");
sum += num;
System.err.println("nums--------:"+sum);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("nums"));
}
}MainTest.java: 测试类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class MainTest {
/**
* 测试
*
* @param args 命令行参数
*/
public static void main(String[] args) {
// 创建拓扑构建者对象
TopologyBuilder builder = new TopologyBuilder();
// 设置 spout
builder.setSpout("wsspout", new WsSpout());
// 设置 blot
builder.setBolt("wsbolt", new WsBlot()).shuffleGrouping("wsspout");
// 创建本地集群
LocalCluster locCluster = new LocalCluster();
// 提交拓扑
locCluster.submitTopology("ws", new Config(), builder.createTopology());
}
}
Storm Word Count
WcSpout.java: 发送消息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class WcSpout extends BaseRichSpout {
SpoutOutputCollector collector;
String[] artile = { "WelCome to Bejing", "WelCome to AnHui", "WelCome to Lujiang" };
Random random = new Random();
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
public void nextTuple() {
List val = new Values(artile[this.random.nextInt(artile.length)]);
this.collector.emit(val);
System.err.println("line--------:"+val.get(0));
Utils.sleep(2000);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}WcBolt1.java: 对一行数据进行切分,分别发送给下一个 bolt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class WcBolt1 extends BaseRichBolt {
OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
String line = input.getString(0);
String[] words = line.split(" ");
for (String wd : words) {
List val = new Values(wd);
this.collector.emit(val);
//System.err.println("wcbolt1.......:"+wd);
}
Utils.sleep(200);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("wd"));
}
}WcBolt2.java:统计单词的次数,并放入 Map 集合中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32public class WcBolt2 extends BaseRichBolt {
OutputCollector collector;
Map<String, Integer> wordCount =new HashMap<>();
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
// Welcome
String wd = input.getStringByField("wd");
if (this.wordCount.containsKey(wd)) {
int count = this.wordCount.get(wd);
this.wordCount.put(wd, ++count);
} else {
this.wordCount.put(wd, 1);
}
System.err.println(this.wordCount);
Utils.sleep(500);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("w"));
}
}WordCountMainTest.java: 测试类
1
2
3
4
5
6
7
8
9
10
11
12public class WordCountMainTest {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("wcspout", new WcSpout());
builder.setBolt("wcbolt1", new WcBolt1()).shuffleGrouping("wcspout");
// fieldGrouping: 数据分发策略
builder.setBolt("wcbolt2", new WcBolt2(),3).fieldsGrouping("wcbolt1", new Fields("wd"));
// builder.setBolt("wcbolt2", new WcBolt2()).shuffleGrouping("wcbolt1");
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordcount", new Config(), builder.createTopology());
}
}
Storm 数据分发策略*
Shuffle Grouping*
随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
轮询,平均分配Fields Grouping*
按字段分组,比如,按”user-id”这个字段来分组,那么具有同样”user-id”的 tuple 会被分到相同的Bolt里的一个task, 而不同的”user-id”则可能会被分配到不同的task。All Grouping*
广播发送,对于每一个tuple,所有的bolts都会收到Global Grouping
全局分组,把tuple分配给task id最低的task 。None Grouping
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果。 有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(未来Storm如果可能的话会这样设计)。Direct Grouping
指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)Local or shuffle grouping
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致customGrouping
自定义,相当于mapreduce那里自己去实现一个partition一样。
Storm 架构设计*

角色作用
Nimbus- 资源调度
- 任务分配
- 接收 jar 包
Supervisor- 接收
nimbus分配的任务 - 启动、停止自己管理的 worker 进程(当前 supervisor 上 worker 数量由配置文件设定)
- 接收
Worker- 运行具体处理运算组件的进程(每个Worker对应执行一个Topology的子集)
- worker 任务类型,即 spout 任务、bolt 任务两种
- 启动 executor
(executor即worker JVM进程中的一个java线程,一般默认每个executor负责执行一个task任务)
Zookeeper- 负责角色的健康检查
Storm 架构与 Hadoop 架构比较
| Hadoop | Storm | |
|---|---|---|
| 主节点 | ResourceManager | Nimbus |
| 从节点 | NodeManager | Supervisor |
| 应用程序 | Job | Topology |
| 工作进程 | Child | Worker |
| 计算模型 | Map/Reduce(split,map,shuffle,reduce) | Spout/Bolt |
Storm 任务提交流程

Storm 并发机制*
Worker Executor Task 之间的联系
- Work Process 进程
一个 Topology 拓扑会包含一个或多个 Worker(每个Worker进程只能从属于一个特定的Topology)
这些Worker进程会并行跑在集群中不同的服务器上,即一个Topology拓扑其实是由并行运行在Storm集群中
多台服务器上的进程所组成
Executor (Threads) 线程
Executor 是由 Worker 进程中生成的一个线程
每个 Worker 进程中会运行拓扑当中的一个或多个 Executor 线程
一个 Executor 线程中可以执行一个或多个 Task 任务(默认每个Executor只执行一个Task任务),但是这些
Task 任务都是对应着同一个组件(Spout、Bolt)。
Task 任务
实际执行数据处理的最小单元,每个 task 即为一个 Spout 或者一个 Bolt
Task 数量在整个 Topology 生命周期中保持不变,Executor 数量可以变化或手动调整
默认情况下,Task 数量和 Executor 是相同的,即每个 Executor 线程中默认运行一个 Task 任务

调整 Worker Executor Task 的数量
设置 Worker 进程数
1
Config.setNumWorkers(int workers)
设置 Executor 线程数
1
2
3
4TopologyBuilder.setSpout(String id, IRichSpout spout, Number parallelism_hint)
TopologyBuilder.setBolt(String id, IRichBolt bolt, Number parallelism_hint)
//:其中, parallelism_hint即为executor线程数设置 Task 数量
1
ComponentConfigurationDeclarer.setNumTasks(Number val)
例:
1
2
3
4
5
6
7
8Config conf = new Config() ;
conf.setNumWorkers(2);
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("spout", new MySpout(), 1);
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout);
rebalance 再平衡
动态调整 Topology 拓扑的 Worker 进程数量、以及 Executor 线程数量
支持两种调整方式:
1、通过 Storm UI
2、通过 Storm CLI
通过 Storm CLI 动态调整:
例:storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
将mytopology拓扑worker进程数量调整为5个
“ blue-spout ” 所使用的线程数量调整为3个
“ yellow-bolt ”所使用的线程数量调整为10个
Storm 通信机制
Worker 进程间的数据通信
- ZMQ
ZeroMQ 开源的消息传递框架,并不是一个MessageQueue - Netty
Netty是基于 NIO 的网络框架,更加高效。(之所以Storm 0.9版本之后使用 Netty,是因为ZMQ的license和Storm的license不兼容。)
Worker内部的数据通信*
Disruptor 实现了“队列”的功能。可以理解为一种事件监听或者消息处理机制,即在队列当中一边由生产者放入消息数据,另一边消费者并行取出消息数据处理。

Storm 安装
伪分布式
系统环境
- Java 环境
搭建
伪分布式搭建在节点 node01(192.168.170.101)上
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32上传 storm 软件压缩包到 Linux 服务器上
tar xf apache-storm-0.10.0.tar.gz -C /opt/sxt
配置 storm 环境变量
export STORM_HOME=/opt/sxt/apache-storm-0.10.0
export PATH=$PATH:$STORM_HOME/bin
cd $STROM_HOME 根目录
首先启动 dev-zookeeper
storm dev-zookeeper >> ./logs/dev-zookeeper.out 2>&1 &
再启动 nimbus
storm nimbus >> ./logs/nimbus.out 2>&1 &
再启动 spervisor
storm supervisor >> ./logs/supervisor.out 2>&1 &
最后启动 ui,注意:使用 jps 命令查看 ui 进程的名称为 core
storm ui >> ./logs/ui.out 2>&1 &
使用 jps 命令
[root@node01 apache-storm-0.10.0]# jps
4661 nimbus
3932 DFSZKFailoverController
4998 Jps
4895 core
4563 dev_zookeeper
4805 supervisor
3790 JournalNode
打开 node01:8080 端口
http://node01:8080小技巧: 通过
storm 或者 storm help查看命令的如何使用。storm help 参数查看具体命令的使用部署伪分布式任务
在部署之前,确保 storm 中的必要的角色(zk、nimbus、supervisor)都已经启动
1
2
3
4将 IDE 中的项目打包成 jar 文件,并上传到 Linux 服务器上
运行 jar 包
storm jar jar的位置 类的全限定路径名 [参数]
若未给定参数,则在本地运行。若给定参数,则将提交给集群运行
完全分布式
节点分布
host/role 192.168.170.102/node02 192.168.170.103/node03 192.168.170.104/node04 nimbus * supervisor * * worker * * * 系统环境
- 安装 Java 环境 ,并保证 JDK 版本在 1.6 以上
- 安装 Python 环境,并保存 Python 在 2.6.6 以上即可
Storm 完全分布式搭建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41上传 storm软件压缩包 到 node02 节点 上
解压
tar zxvf apache-storm-0.10.0.tar.gz -C /opt/sxt
配置 storm 环境变量
进入 $STROM_HOME 根目录下
cd conf
编辑 storm.yaml 文件,内容如下:
storm.zookeeper.servers:
- "node02"
- "node03"
- "node04"
nimbus.host: "node02"
storm.local.dir: "/tmp/storm"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
分发到 node03、node04 节点上
scp -r apache-storm-0.10.0/ root@node03:`pwd`
scp -r apache-storm-0.10.0/ root@node04:`pwd
-------------------------------------------------------
以下操作都是在 $STROM_HOME 根目录下执行的
在 node02、node03、node04 节点上创建 logs 目录
mkdir logs
在 node02 启动
storm nimbus >> ./logs/nimbus.out 2>&1 &
storm ui >> ./logs/ui.out 2>&1 &
node03、node04 启动
storm supervisor >> supervisor.out 2>&1 &
访问 http://node02:8080
上传任务 jar
storm jar jar的路径 主类的全限定路径名 任务名
Storm 容错保护机制
集群节点宕机
Nimbus服务器
单点故障?当 Nimbus 出现了宕机,并不会直接影响 Storm 的运行,因为 Nimbus 并不是直接与 Supervisor 进行交互,而是与 Zookeeper 协调者之间进行交互,即 Zookeeper 将 Nimbus 与 Supervisor 的直接关系,转为间接关系。但有一个情况下,Supervisor 中某个节点宕机了,Zookeeper 会该 Supervisor 消息传递给 Nimbus,这时 Nimbus 必须宕机后恢复重启,继续工作。
非 Nimbus 服务器
故障时,该节点上所有 Task 任务都会超时,Nimbus 会将这些 Task 任务重新分配到其他服务器上运行
进程挂掉
- Worker
挂掉时,Supervisor会重新启动这个进程。如果启动过程中仍然一直失败,并且无法向Nimbus发送心跳,Nimbus会将该Worker重新分配到其他服务器上 - Supervisor
无状态(所有的状态信息都存放在Zookeeper中来管理)
快速失败(每当遇到任何异常情况,都会自动毁灭) - Nimbus
无状态(所有的状态信息都存放在Zookeeper中来管理)
快速失败(每当遇到任何异常情况,都会自动毁灭)
消息的完整性
从Spout中发出的Tuple,以及基于他所产生Tuple(例如上个例子当中Spout发出的句子,以及句子当中单词的tuple等)由这些消息就构成了一棵tuple树。当这棵tuple树发送完成,并且树当中每一条消息都被正确处理,就表明spout发送消息被“完整处理”,即消息的完整性

ack 机制 –消息完整性的实现机制
- Storm的拓扑当中特殊的一些任务
- 负责跟踪每个Spout发出的Tuple的DAG(有向无环图)
注意:ack 无法保证数据不被重复计算,但是可以保证数据至少被正确处理一次。
在实际的使用中,由于处理的整体数据量大,出现个别消息不完整,是可以容忍的。
事务
无,后续
DRPC -同步实时分析
Distributed Remote Procedure Call
DRPC 是通过一个 DRPC 服务端(DRPC server)来实现分布式 RPC 功能的。
DRPC Server 负责接收 RPC 请求,并将该请求发送到 Storm中运行的 Topology,等待接收 Topology 发送的处理结果,并将该结果返回给发送请求的客户端。
(其实,从客户端的角度来说,DPRC 与普通的 RPC 调用并没有什么区别。)
DRPC设计目的:
为了充分利用 Storm 的计算能力实现==高密度的并行实时计算==,Storm 接收若干个数据流输入,数据在 Topology 当中运行完成,然后通过 DRPC 将结果进行输出。
DRPC架构图
客户端通过向 DRPC 服务器发送待执行函数的名称以及该函数的参数来获取处理结果。实现该函数的拓扑使用一个 DRPCSpout 从 DRPC 服务器中接收一个函数调用流。DRPC 服务器会为每个函数调用都标记了一个唯一的 id。随后拓扑会执行函数来计算结果,并在拓扑的最后使用一个名为 ReturnResults 的 bolt 连接到 DRPC 服务器,根据函数调用的 id 来将函数调用的结果返回。

DRPC 实现
- 通过 LinearDRPCTopologyBuilder (该方法也过期,不建议使用)
该方法会自动为我们设定 Spout、将结果返回给 DRPC Server 等,我们只需要将 Topology 实现
1 | /** |
- 直接通过普通的拓扑构造方法 TopologyBuilder 来创建 DRPC 拓扑,需要手动设定好开始的 DRPCSpout 以及结束的 ReturnResults
1 | public class ManualDRPC { |
DRPC 远程模式
节点分布
host/role node02 node03 node04 nimbus * supervisor * * drpc * 在 storm 完全分布式的基础上,修改 storm.yarm 文件
1
2
3
4
5
6
7
8
9
10
11
12cd $STORM_HOME/conf/
修改配置文件conf/storm.yaml
drpc.servers:
- "node1“
启动DRPC Server
bin/storm drpc &
通过StormSubmitter.submitTopology提交拓扑
StormSubmitter
.submitTopologyWithProgressBar(args[0], conf, builder.createRemoteTopology());
DRPC 客户端代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class MyDRPCclient {
/**
* @param args
*/
public static void main(String[] args) {
DRPCClient client = new DRPCClient("node02", 3772);
try {
String result = client.execute("exclamation", "11,22");
System.out.println(result);
} catch (TException e) {
e.printStackTrace();
} catch (DRPCExecutionException e) {
e.printStackTrace();
}
}
}
kafka*
Kafka 是一个分布式的消息队列系统 (Message Queue)。

kafka 集群有多个 Broker 服务器组成,每个类型的消息被定义为 topic。
同一 topic 内部的消息按照一定的 key 和算法被分区 (partition) 存储在不同的 Broker上。
消息生产者 producer 和消费者 consumer 可以在多个 Broker上生产/消费 topic
Topics and Logs:
Topic 即为每条发布到 Kafka 集群的消息都有一个类别,topic 在 Kafka 中可以由多个消费者订阅、消费。
每个 topic 包含一个或多个partition(分区),partition 数量可以在创建 topic 时指定,每个分区日志中记录了该分区的数据以及索引信息。如下图:

Kafka 只保证一个分区内的消息有序,不能保证一个主题的不同分区之间的消息有序。
如果你想要保证所有的消息都绝对有序可以只为一个主题分配一个分区。
分区会给每个消息记录分配一个顺序 ID 号(偏移量), 能够唯一地标识该分区中的每个记录。
Kafka 集群保留所有发布的记录,不管这个记录有没有被消费过,Kafka 提供相应策略通过配置从而对旧数据处理。

实际上,每个消费者唯一保存的元数据信息就是消费者当前消费日志的位移位置。位移位置是由消费者控制,即、消费者可以通过修改偏移量读取任何位置的数据。
角色
Distribution – 分布式
Producers – 生产者
指定 topic 来发送消息到 Kafka Broker
Consumers – 消费者
根据 topic 消费相应的消息
Kafka集群部署
集群规划
node02/192.168.170.102 node03/192.168.170.103 node04 /192.168.170.104 zookeeper * * * kafka * * * 安装与配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16在 node02 节点上
上传 kakfa 软件安装包到 Linux 服务器上
解压到指定目录下 /opt/sxt
tar xf kafka_2.10-0.9.0.1.tgz -C /opt/sxt
配置环境变量
export KAFKA_HOME=/opt/sxt/kafka_2.10-0.9.0.1
进入 $KAFKA_HOME/config 下
修改 vi server.properties 文件
root directory for all kafka znodes.
zookeeper.connect=node02:2181,node03:2181,node04:2181
分发,进入 /opt/sxt 目录下
scp -r kafka_2.10-0.9.0.1/ node03:`pwd`
scp -r kafka_2.10-0.9.0.1/ node04:`pwd`
在 node03、node04 节点上修改 server.proerties
The id of the broker. This must be set to a unique integer for each broker.
broker.id=1启动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26进入 $KAFKA_HOME
bin/kafka-server-start.sh config/server.properties # 阻塞当前窗口
新打开一个 shell 窗口,node02
创建 topic
kafka-topics.sh --zookeeper node02:2181,node03:2181,node04:2181 --create --replication-factor 2 --partition 3 --topic test
查看创建好的 topic
kafka-topics.sh --zookeeper node02:2181,node03:2181,node04:2181 --list
(参数说明:
--replication-factor:指定每个分区的复制因子个数,默认1个
--partitions:指定当前创建的kafka分区数量,默认为1个
--topic:指定新建topic的名称)
查看 “test” topic 的描述
kafka-topics.sh --zookeeper node02:2181,node03:2181,node04:2181 --describe test
Topic:test PartitionCount:3 ReplicationFactor:2 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: test Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: test Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1
创建生产者
kafka-console-producer.sh --broker-list node02:9092,node03:9092,node04:9092 --topic test
创建消费者
kafka-console-consumer.sh --zookeeper node02:2181,node03:2181,node04:2181 --from-beginning --topic test
kafka 与 flume 整合
安装 flume
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29解压jar包
mv conf/flume-env.sh.template flume-env.sh
vi flume-env.sh java环境变量
./bin flume-ng version
/conf/下 创建配置文件fk.conf内容如下:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = node01
a1.sources.r1.port = 41414
Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = testflume
a1.sinks.k1.brokerList = node02:9092,node03:9092,node04:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 10000
Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动
1
2
3
4
5
6
7
8
9
10
11
12启动zk集群
A、启动Kafka集群。
kafka-server-start.sh config/server.properties
B、配置Flume集群,并启动Flume集群。 # 注意在存在 kafka.conf 的目录中启动
flume-ng agent -n a1 -c conf -f kafka.conf -Dflume.root.logger=DEBUG,console
创建 topic testflume 消费者
kafka-console-consumer.sh --zookeeper node02:2181,node03:2181,node04:2181 --from-beginning --topic testflume
创建 topic LogError 消费者
kafka-console-consumer.sh --zookeeper node02:2181,node03:2181,node04:2181 --from-beginnin --topic LogErrorJava 发送 RPC 到 Flume
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62/**
* Flume官网案例
* http://flume.apache.org/FlumeDeveloperGuide.html
* @author root
*/
public class RpcClientDemo {
public static void main(String[] args) {
MyRpcClientFacade client = new MyRpcClientFacade();
// Initialize client with the remote Flume agent's host and port
client.init("node01", 41414);
// Send 10 events to the remote Flume agent. That agent should be
// configured to listen with an AvroSource.
for (int i = 100; i < 110; i++) {
String sampleData = "Hello Flume! ERROR" + i;
client.sendDataToFlume(sampleData);
System.out.println("发送数据:" + sampleData);
}
client.cleanUp();
}
}
class MyRpcClientFacade {
private RpcClient client;
private String hostname;
private int port;
public void init(String hostname, int port) {
// Setup the RPC connection
this.hostname = hostname;
this.port = port;
this.client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of the
// above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
public void sendDataToFlume(String data) {
// Create a Flume Event object that encapsulates the sample data
Event event = EventBuilder.withBody(data, Charset.forName("UTF-8"));
// Send the event
try {
client.append(event);
} catch (EventDeliveryException e) {
// clean up and recreate the client
client.close();
client = null;
client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of
// the above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
}
public void cleanUp() {
// Close the RPC connection
client.close();
}
}
flume 与 Storm 整合
http://storm.apache.org/about/integrates.html
Flume 、Storm 、Kafka 整合架构

项目案例
模拟电信项目
过
事务
事务性拓扑(Transactional Topologies)
保证消息(tuple)被且仅被处理一次
Design1
强顺序流(强有序)

引入事务(transaction)的概念,每个transaction(即每个tuple)关联一个transaction id。
Transaction id 从 1开始,每个 tuple 会按照顺序+1。
在处理 tuple 时,将处理成功的 tuple 结果以及 transaction id 同时写入数据库中进行存储。
两种情况:
1、当前transaction id与数据库中的transaction id不一致
2、两个transaction id相同
缺点:
一次只能处理一个tuple,无法实现分布式计算
Design2
强顺序的Batch流

事务(transaction)以 batch 为单位,即把一批 tuple 称为一个 batch,每次处理一个 batch。
每个 batch(一批 tuple)关联一个 transaction id
每个 batch 内部可以并行计算
缺点:空余占用资源

Design3
Storm’s design
将 Topology 拆分为两个阶段:
- Processing phase
允许并行处理多个 batch - Commit phase
保证batch的强有序,一次只能处理一个batch
- Processing phase
Design details
Manages state - 状态管理
Storm 通过 Zookeeper 存储所有 transaction 相关信息(包含了:当前transaction id 以及batch的元数据信息)Coordinates the transactions - 协调事务
Storm 会管理决定 transaction 应该处理什么阶段(processing、committing)Fault detection - 故障检测
Storm 内部通过 Acker 机制保障消息被正常处理(用户不需要手动去维护)First class batch processing API
Storm 提供 batch bolt 接口
三种事务
1、普通事务
2、Partitioned Transaction - 分区事务
3、Opaque Transaction - 不透明分区事务